I Tried Every Speech-to-Text App Out There: Here’s What You Need to Know
Python: The programming language of choice for implementing and testing STT processes.
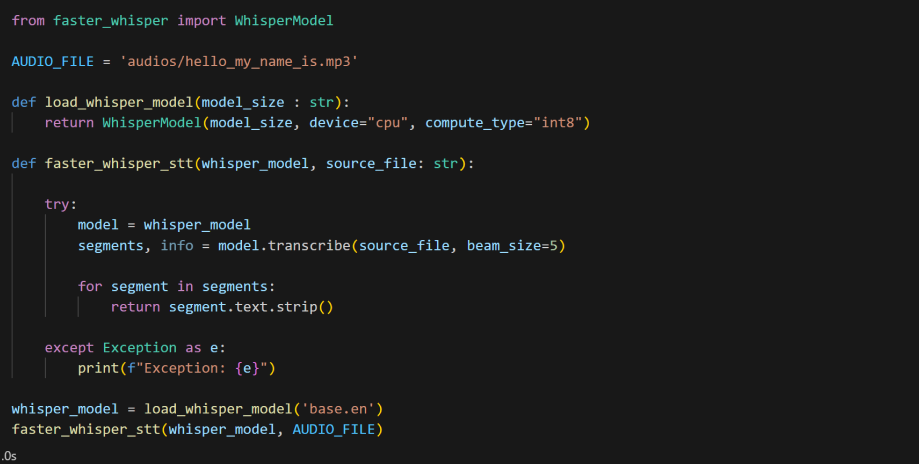
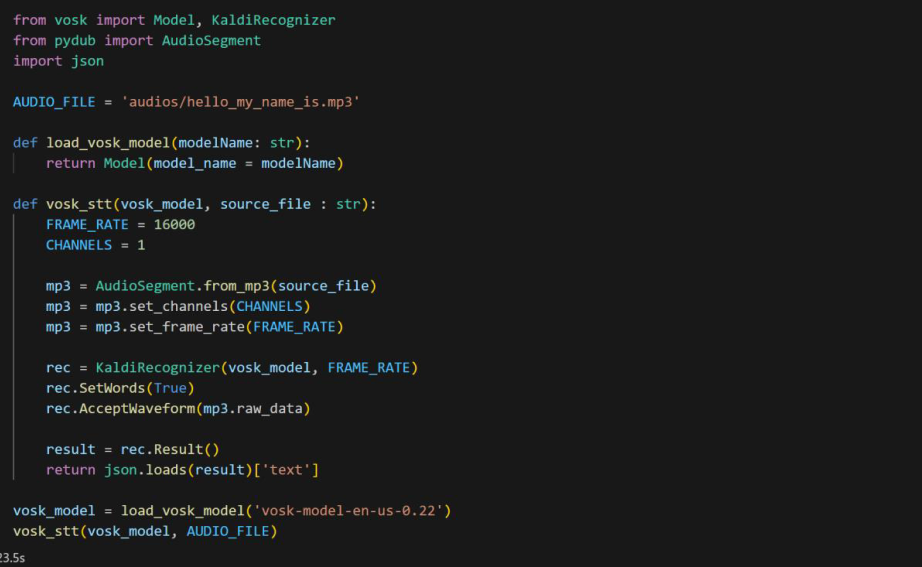
Speech-to-Text Engines: The core components responsible for the transcription of spoken words into text.
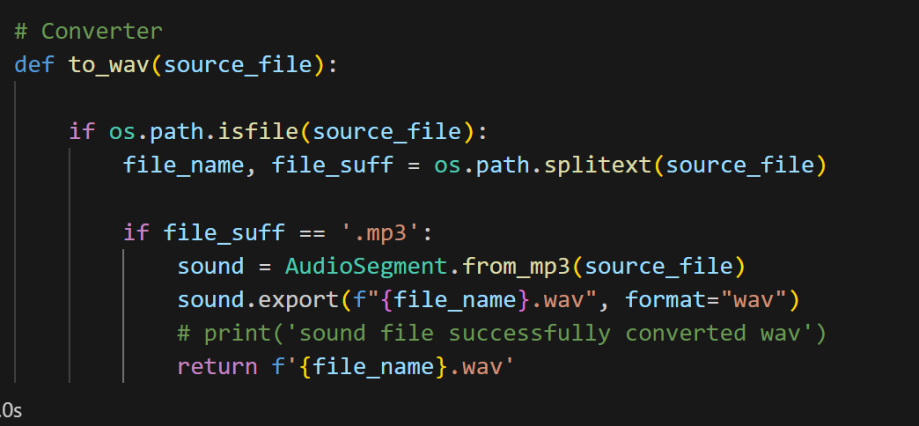
Audio Processing Tools: Essential for preparing audio files for transcription, including Pyaudio for recording and playback, Ffmpeg for multimedia processing, and Pydub for audio manipulation.